Big O allows us to group routines based on their projected performance under different conditions (best case, worst case, etc). Remember that Big O is only an estimate. It does not take into account factors specific to a particular environment, such the specific implementation, the type of computer system we are using, and the data that we are processing.
To determine how well or poorly a routine will perform in a particular environment, we need to evaluate the routine in that environment.
Big O notation is typically divided into predefined classifications that group functions based on them having similar running speed. For example, we have:
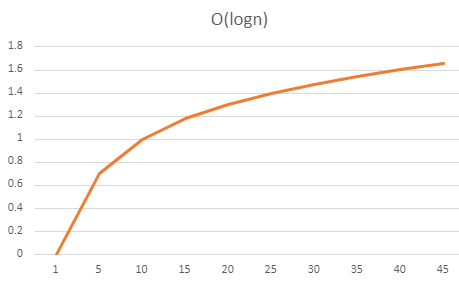
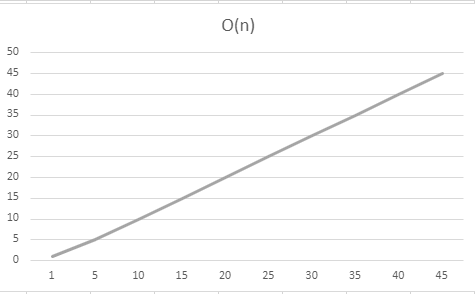
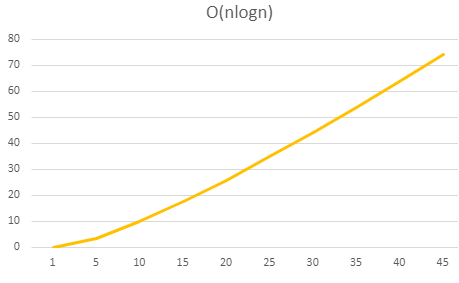
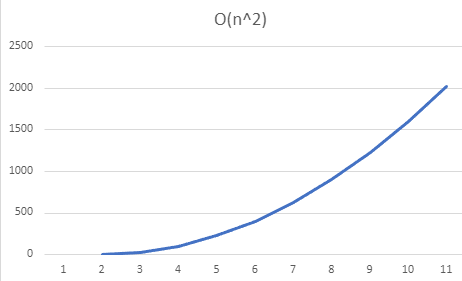
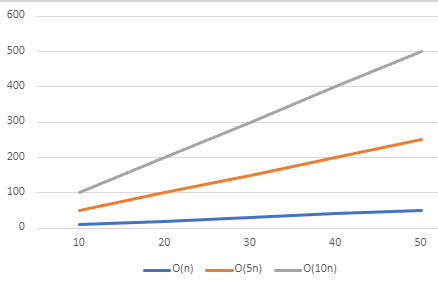
In practice, the lines will never exactly match these ones, but you can still identify the classification by examining the general shape
When we consider Big O notation, we do not really care about the specific numbers involved - we simply want to measure the rate something is increasing. This means that
when you are using Big O notation, you simplify out the constants. A linear function of O(n) will still be considered to have the same rate of growth as O(10n), as both will
be lines, even if one is steeper. All of the lines below would still be considered to have the same rate of growth of O(n).
In summary, for the binary search, you are given a sorted array. The idea is to divide the array into two equal parts and narrow down the range of the array to be searched either to the low part of the array or high part of the array. We will continue narrowing down the range until the value is located, or until we realize that the value searched for is not in the array.
The linear search is also known as the sequential search. The idea is start with the first element, and sequentially search through the array until we find a match.
Before we can measure the performance of these routines, we must first develop a set of tools that allow us to measure the execution time.
The general approach will be the following:
Download three files. Get the files by right click on the file name and save as:
Store the three files where you can easily find them.
A library is a collection of object files - .obj or .o files which you've been using in Unix. . Object files can contain individual functions, collections of functions or an entire class implementation. Each object file is stored individually. When your program references a function or class contained in a library, it links the object it belongs to and adds its code to your program. This way you can have one big file to store related things but only the pieces that you actually use in your program are added to the executable file.
Each function or class defined in the C or C++ standard library has a
header file associated with it. The header files that relate to
the functions that you use in your programs should be
included (using #include) in your program.
There are
two reasons for this:
Interestingly one library may have more than one header file.
Libraries can be regarded as pre-compiled functions or classes that do not need to be re-compiled if other parts of your project change. If you have a "bug-free" module (a piece of self-contained code) that could be reused with other projects, you can compile this module to a library. After you link this library to your new project, you will then be able to use any of the functions or classes in this library as if they are defined locally in your project. One major advantage is that the functions or classes in the library will not be recompiled, which saves time compiling your entire project.
In our example, "timer" is a perfect candidate: it does not contain any bugs and we can use it again in other projects.
To use "timer" in a new project, we will have to first compile the C++ programs into a library, and then link this library to the new project.In this program, timer.h and timer.cpp define and implement a time measuring class Timer. This class is independent of the kind of program it is measuring. In other words, we can reuse this Timer class to measure the running time of other programs. It naturally follows that once we make this class bug-free, we can compile it into a library. To use this time-measuring class, we simply include the header file (i.e.timer.h) in the program and link the library to this program.
The following shows you how we do this:
In the command line, write the following to create a timer object file:
g++ -c timer.cpp -o timer.o
next, compile the object(s) into an archive file (.a):
ar rcs timerlib.a timer.o
To test the library:
g++ complexity.cpp timerlib.a ./a.out
You will analyse the execution times of three searching routines.
timesrch.cpp , search.h , and sort.h
Your primary tasks for this exercise are:
Steps include:
language = "c++" run = "g++ timesrch.cpp timerlib.a -o output; ./output"
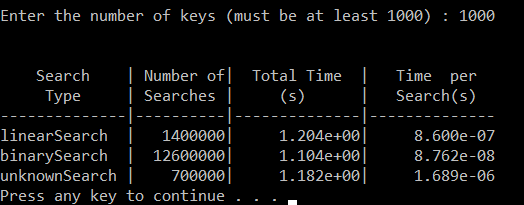
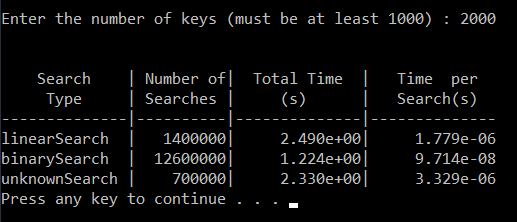
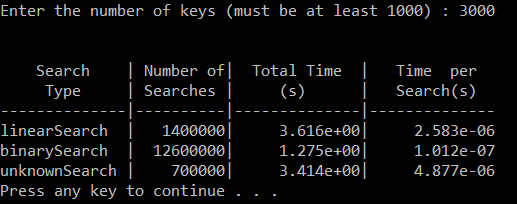
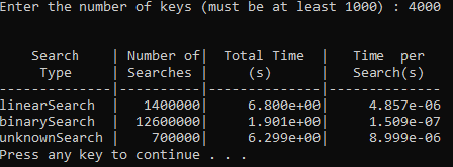
Enter the number of keys (must be at least 1000) : 1000
Search | Number of| Total Time | Time per
Type | Searches | (s) | Search(s)
--------------|----------|--------------|--------------
linearSearch | 1400000| 3.898e+000| 2.784e-006
binarySearch | 12600000| 1.813e+000| 1.439e-007
unknownSearch | 700000| 3.866e+000| 5.523e-006
The 2.087e-004 is equivalent to 2.087*10-4 or 0.0002087.
 |
 |
 |
 |
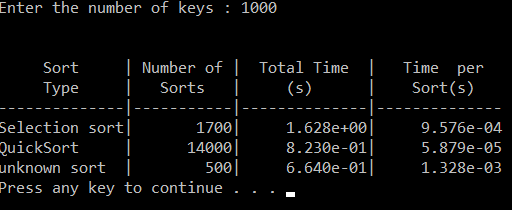
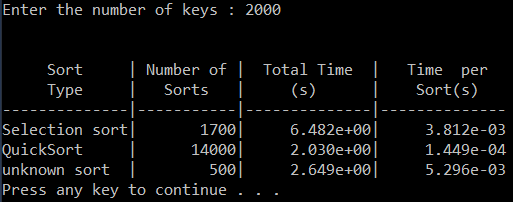
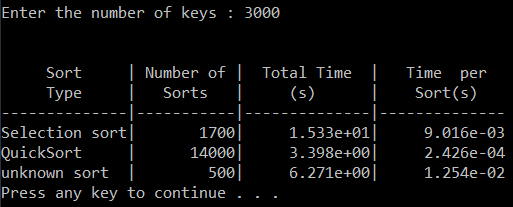
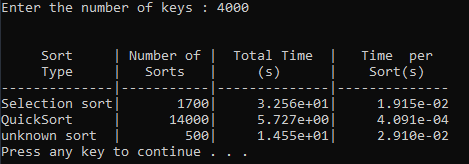
timesort.cpp and sort.h
Your primary tasks for this exercise are:
 |
 |
 |
 |
|
|
|